
Following up on my TOP500 list by interconnect post, here’s a update with the latest, June 2010 TOP500 list.
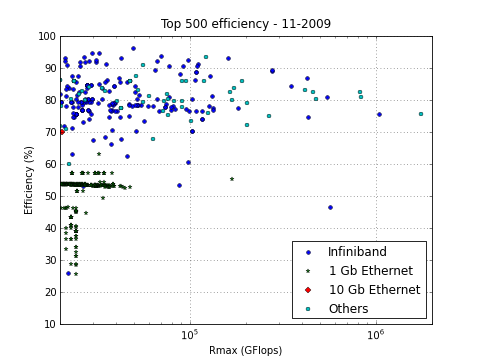
First, for comparison, here’s the November 2009 version at the same scale:
And this is how the list looks now:
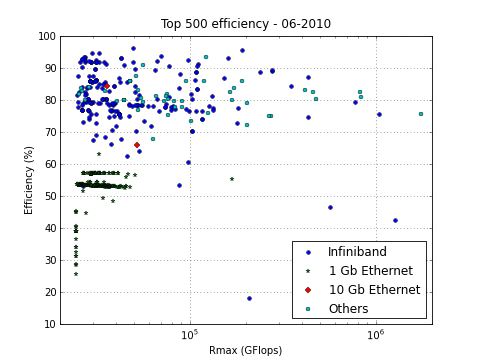
For one, given the number of recent announcements around it, I was expecting for 10G-Ethernet to gain some more adoption by now. Yet (assuming those details in the TOP500 list – and my parsing of it – are correct), only two new systems use 10G-Eth while those that were in last November’s list have now fallen out.
But something much more interesting seems to be happening at the lower right corner of the graph (look at the three blue (Inifiniband) dots nearest to the legend, interestingly, all three systems are Chinese). The Tianhe-1 hybrid Intel Xeon + ATI Radeon cluster (now at #7) got some company from two more GPGPU clusters, Mole-8.5 at #19 and even the new #2, Nebulae. They are characterized by a rather low efficiency – especially for this part of the ranking. Note that no-one else in the right half fools around with mere Gigabit Ethernet or otherwise has an efficiency that is lower than 70%. Yet the number two of this list only manages a 43% efficiency, and needs 2984 GFLOPS of raw computing power (28% more than the #1 system, Jaguar) to get at a LINPACK score of 28% less than Jaguar’s.
The explanation for this lies in two numbers that are not shown in this graph: power and cost. Just like the commodity-based clusters started to take over from the hard-core custom-built supercomputers some 10 years ago, the GPGPU-based system may very well be on its way to take over the charts. They follow the same basic recipe as those Beowulf-inspired clusters: a not-so-great efficiency, which is cured with loads of cheap, low-power processing power.
The efficiency of the cluster improved drastically over time, using better interconnect such as Infiniband. The cluster idea is now so prevalent that over 80% of the systems in the Top500 today should be categorized as clusters. The next question is how GPGPU will evolve into something that can combine its advantages of low cost and low power with increased efficiency. Nvidia has some clear ideas about HPC being the future for their products (although their first step, Fermi, got executed rather strangely…). ATI/AMD are also hard at work with FireStream and OpenCL. And coming from the other side of the arena, we have the general purpose processors moving towards simpler, but many more cores per chip, an idea embodied in the form of (among many others) Tilera’s TILE family or Intel’s SCC.
Interesting times again loom ahead. Let the games, eh computations, begin!